

AI Co-Scientist: A New Paradigm for Accelerating Scientific Discovery

Executive Summary
Google researchers have introduced the "AI co-scientist," a multi-agent system built on Gemini 2.0 that serves as a virtual scientific collaborator to accelerate hypothesis generation and research proposal development. The system employs a "generate, debate, evolve" approach inspired by the scientific method to iteratively improve hypothesis quality through test-time compute scaling. Validated across three biomedical domains with increasing complexity—drug repurposing, novel target discovery, and antimicrobial resistance mechanisms—the system has demonstrated its ability to generate novel, testable hypotheses with promising wet-lab validation results.
Introduction: The Scientific Discovery Bottleneck
The pace of scientific discovery faces a fundamental constraint: researchers must navigate an exponentially growing corpus of literature while simultaneously developing novel hypotheses. This challenge is particularly acute at the boundaries between disciplines, where breakthrough innovations often emerge but where few scientists possess sufficient cross-domain expertise.
Previous Work:
Reasoning models and test-time compute scaling
The test-time compute paradigm enhances model reasoning capabilities by allocating additional computational resources during inference, demonstrated in early systems like AlphaGo and Libratus through approaches like Monte Carlo Tree Search to explore game states strategically.
Large language models benefit from test-time compute, allowing more thorough exploration of possible responses and improving reasoning accuracy, with recent advancements like Deepseek-R1 showing potential through reinforcement learning.
The paper proposes significant scaling of test-time compute using multi-agent systems with inductive biases derived from the scientific method, without requiring additional learning techniques.
AI-driven scientific discovery
Recent progress has shifted from specialized AI models like AlphaFold 2 toward integrating general-purpose LLMs into the complete research workflow, from hypothesis generation to manuscript writing.
Prior systems like PaperQA2, HypoGeniC, and "data-to-paper" focus on specific aspects of the scientific process but lack the kind of end-to-end validation demonstrated in the current work.
Systems like Virtual Lab and "The AI Scientist" share similarities with this work but differ in their approach to test-time compute scaling and lack comprehensive validation across multiple scientific domains.
AI for biomedicine
Both general-purpose (GPT-4, Gemini) and specialized LLMs (Med-PaLM, Med-Gemini), among others, show strong performance on biomedical reasoning and question-answering benchmarks.
Specialized foundation models trained on biological sequences (DNA, RNA, protein) have been developed alongside general-purpose models, with recent progress blurring the distinction between specialized and general AI systems.
The paper focuses on three use cases: drug repurposing as a validation domain, target identification and hypothesis generation.
The Multi-Agent Architecture: Mirroring Scientific Collaboration
The AI co-scientist generates hypothesis and research proposals that adhere to five default criteria: alignment with the provided research goal, plausibility (logical soundness), novelty (original contributions), testability (empirical validation), and safety (ethical research).
The AI co-scientist multi-agent architecture design.
The AI co-scientist architecture features a collection of specialized agents that emulate distinct cognitive processes involved in scientific reasoning:
Generation Agent: Explores literature, synthesizes existing findings, and produces initial hypotheses through multiple approaches including simulated scientific debates and iterative assumption identification.
Reflection Agent: Acts as a peer reviewer, critically examining hypothesis correctness, quality, novelty, and safety through various review types including initial assessment, full literature-grounded evaluation, deep verification, and observation review. It can search relevant prior work by web search or a dedicated scientist-provided repository
Ranking Agent: Employs an Elo-based tournament to assess and prioritize hypotheses through multi-turn scientific debates, focusing on novelty, correctness, and testability.
Proximity Agent: Calculates similarity between hypotheses, building a proximity graph that helps organize tournament matches and display diverse ideas.
Evolution Agent: Continuously refines top-ranked hypotheses through multiple approaches including literature grounding, coherence improvements, combination of ideas, and innovative thinking.
Meta-review Agent: Synthesizes insights from all reviews, identifying patterns to improve future hypothesis generation and reviewing processes, while also producing comprehensive research overviews.
This multi-agent design creates an internal feedback loop allowing for continuous improvement through test-time compute scaling, all without requiring reinforcement learning or additional training. The agents communicate through a shared context memory, and a Supervisor agent manages the task workflow and resource allocation.
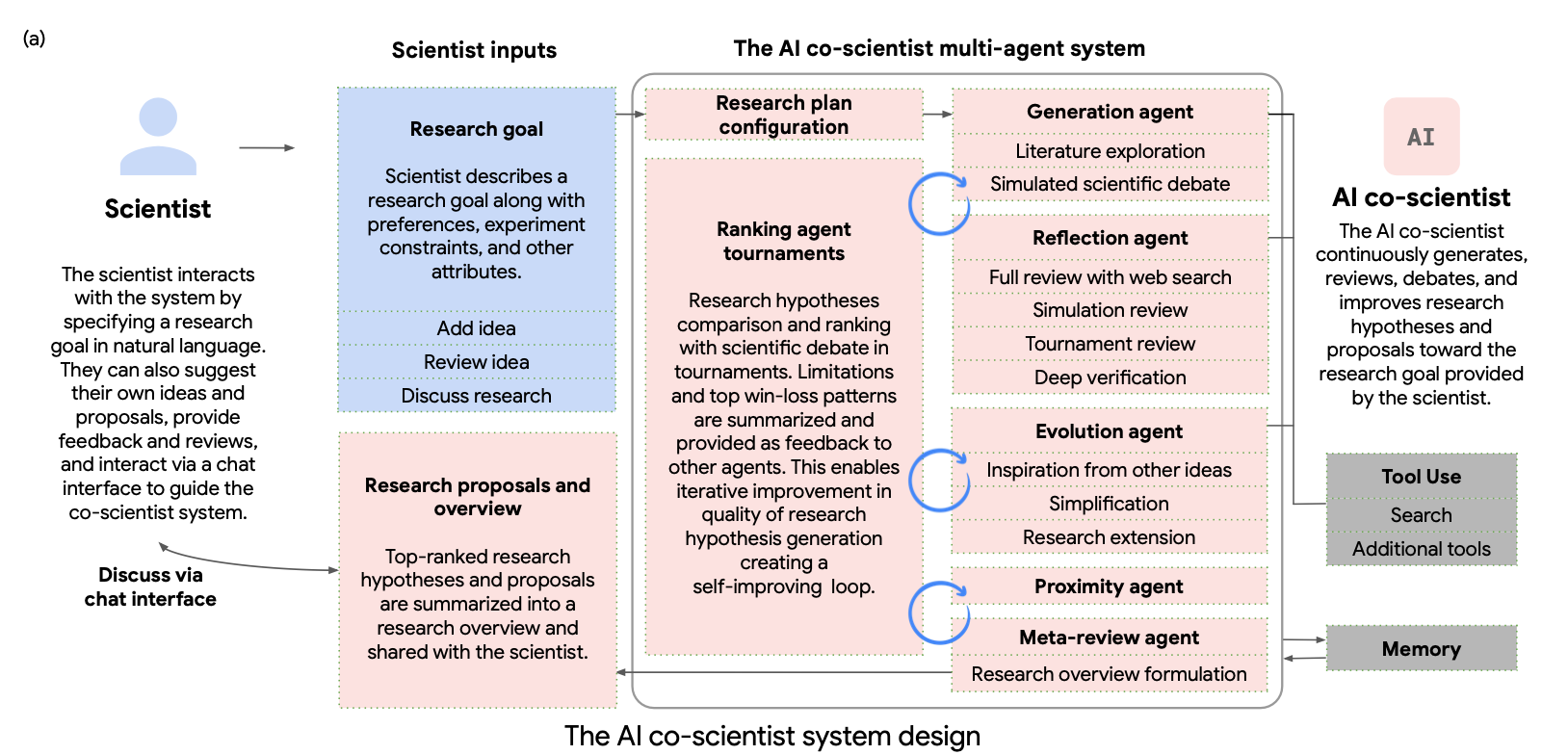
Fig1. The AI co-scientist system design. https://arxiv.org/abs/2502.18864
Tool use in AI co-scientist:
Web search and retrieval are the general primary tools. Domain specific tools such as open databases and indexing and search of specific repositories of publications specified by the scientist. Specialized models like AlphaFold can also be integrated.
Adherence to scientific research criteria:
Furthermore at multiple steps in the process, the agents in the system verify that the hypotheses and research proposals adhere to five default criteria of:

Technical Results:
At the time of development, the following are key innovations:
AI co-scientist system shows significant scaling of test-time compute for scientific reasoning.
Unlike conventional language models that immediately generate responses, the co-scientist allocates substantial computational resources during inference to enable System-2 style thinking—deliberate, slower reasoning that explores multiple solution paths.
The system's self-improvement feedback loops create a virtuous cycle: as more computational resources are allocated, hypothesis quality improves measurably.
When tested on expert-curated research goals, the AI co-scientist significantly outperformed both human experts and state-of-the-art LLM baselines like Gemini 2.0 Pro, OpenAI's o1, and DeepSeek R1 as measured by auto-evaluation Elo ratings.
Newer reasoning models like OpenAI o3-mini and DeepSeek R1 demonstrated competitive performance, while requiring significant less compute and reasoning time as measured by the Elo rating.
The Elo metric is auto-evaluated and not based on independent ground truth. Developing a ground truth benchmark dataset is essential to better evaluate the capabilities of this models.
The researchers observed no evidence of performance saturation, suggesting that further scaling of test-time compute could yield continued improvements in result quality.
Note on the results: While newer models (o3-mini, DeepSeek R1) showed competitive performance with less compute, they weren't evaluated on critical dimensions like novelty and impact. Including this new models might create even more efficient multi-agent systems.
Validation in Critical Biomedical Domains:
The true test of any scientific hypothesis generation system is whether its outputs lead to real-world discoveries. The researchers validated the AI co-scientist across three domains of increasing complexity:
Drug Repurposing: The system identified novel drug candidates for Acute Myeloid Leukemia (AML), including existing drugs with preclinical evidence and completely novel repurposing opportunities. Several candidates—including Binimetinib, Pacritinib, and KIRA6—demonstrated significant tumor inhibition at clinically relevant concentrations in laboratory testing.
Novel Treatment Targets: For liver fibrosis, the co-scientist identified three novel epigenetic targets, with drugs targeting two of these targets showing significant anti-fibrotic activity in human hepatic organoids.
Antimicrobial Resistance Mechanisms: In perhaps the most impressive demonstration, the system independently proposed a hypothesis about how capsid-forming phage-inducible chromosomal islands (cf-PICIs) achieve broad host range—a hypothesis that mirrored unpublished experimental findings by researchers who had been studying this phenomenon for nearly a decade.
Implications for Human-AI Scientific Collaboration
The AI co-scientist represents a paradigm shift in how scientists might interact with AI systems—not as a replacement for human expertise, but as a complementary collaborator that can accelerate hypothesis generation and experimental planning. The system is designed for a "scientist-in-the-loop" paradigm, where domain experts guide exploration and provide feedback.
The system appears particularly valuable for helping scientists identify connections across disciplinary boundaries and for accelerating research in areas with large literature bases that would be challenging for individual researchers to fully synthesize.
Limitations and Future Directions
Key limitations of the paper's methods:
Elo rating limitations - Uses zero-sum competitive framework for hypotheses when scientific discovery is often collaborative; multiple hypotheses can be simultaneously valuable
Benchmark choice - GPQA diamond set uses multiple-choice questions to validate a system designed for open-ended hypothesis generation.
Evaluation subjectivity - Expert evaluations reflect subjective assessments rather than objective ground truth
Incomplete comparison - While newer models (o3-mini, DeepSeek R1) showed competitive performance with less compute, they weren't evaluated on critical dimensions like novelty and impact. Recent architectural innovations in reasoning models may be more efficient than the Gemini multi-agent approach.
Resource scaling - System heavily relies on test-time compute scaling without clear efficiency metrics or cost-benefit analysis. Given the results on the new models (o3-mini, DeepSeek R1) the test-time compute scaling strategy used by the co-scientist system, while effective, might not be the most resource-efficient approach. Future systems might benefit from hybrid approaches that combine efficient reasoning architectures with selective test-time compute scaling
Future improvements could include integration with specialized scientific tools, databases, and AI models; expanded capability to reason over domain-specific biomedical multimodal datasets; and development of better metrics for evaluating hypothesis quality that align more closely with expert preferences.
Questions for Further Reflection
How might scientific research evolve when hypothesis generation can be significantly accelerated?
Could AI co-scientist systems help address the reproducibility crisis by formulating more precise and “codified” hypotheses?
How might R&D organizations include similar systems during their drug development processes?